If you are interested in version control, but have not made the jump yet, the most common reason we’ve heard is how confusing it seems. The best place to start if you are new to version control are the basic concepts.
Why is version control important?
If you are reading this, it’s possible that you are updating documents that look something like this: index-v12-old2.html. Let’s get away from this and on to something that will not only allow you to control your source code and files, but become more productive as a team. If this sounds familiar:
- Communicated with your team via email about updates.
- Made updates directly on your production server.
- Accidentally overwrote some files, which can never be retrieved again.
You can now look forward to this instead:
- File names and directory structures that are consistent for all team members.
- Making changes with confidence, and even reverting when needed.
- Relying on source control as the communication medium for your team.
- Easily deploying different versions of your code to staging or production servers.
- Understanding who made a change and when it happened.
The basic concepts
Tracking changes
A version control system is mostly based around one concept, tracking changes that happen within directories or files. Depending on the version control system, this could vary from knowing a file changed to knowing specific characters or bytes in a file have changed.
In most cases, you specify a directory or set of files that should have their changes tracked by version control. This can happen by checking out (or cloning) a repository from a host, or by telling the software which of your files you wish to have under version control.
The set of files or directories that are under version control are more commonly called a repository.
As you make changes, it will track each change behind the scenes. The process will be transparent to you until you are ready to commit those changes.
Committing
As you work with your files that are under version control, each change is tracked automatically. This can include modifying a file, deleting a directory, adding a new file, moving files or just about anything else that might alter the state of the file. Instead of recording each change individually, the version control system will wait for you to submit your changes as a single collection of actions. In version control, this collection of actions is known as a commit.
Revisions and Changesets
When a commit is made, the changes are recorded as a changeset and given a unique revision. This revision could be in the form of an incremented number (1, 2, 3) or a unique hash (like 846eee7d92415cfd3f8a936d9ba5c3ad345831e5) depending on the system. By knowing the revision of a changeset it makes it easy to view or reference it later. A changset will include a reference to the person who made the commit, when the change was made, the files or directories affected, a comment and even the changes that happened within the files (lines of code).
When it comes to collaboration, viewing past revisions and changesets is a valuable tool to see how your project has evolved and for reviewing teammates’ code. Each version control system has a formatted way to view a complete history (or log) of each revision and changeset in the repository.
Getting updates
As members of your team commit changes, it is important that you have the latest version. Having the latest version reduces the chance of a conflict. Getting the latest changes from a repository is as simple as doing a pull or update from another computer (usually a hosted or centralized server). When an update or pull is requested, only the changes since your last request are downloaded.
Conflicts
What if the latest update or commit results in a conflict? That is, what if your changes are so similar to the changes that another team member made that the version control system can’t determine which is the correct and authoritative change? In most cases, the version control system will provide a way to view the difference between the conflicting versions, allowing you to make a choice. You can either edit the files manually to merge the options, or allow one revision to win over the other. You may want to collaborate with the person who made the other commit to make sure you’re not undoing their important work!
Diffing (or, viewing the differences)
Since each commit is recorded as a change to a file or set of files and directories, it is sometimes useful to view what changed between revisions. For instance, if a recent deployment of your web site is broken and you narrowed down the cause to a particular file, the best action to take is to see what recently changed in that file. By viewing a diff, you can compare two files or even a set of files to see what lines of code changed, when it changed and who changed it. Most version control tools let you compare two sequential revisions, but also two revisions from anywhere in the history.
Branching and merging
There are some cases when you want to experiment or commit changes to the repo that could break things elsewhere in your code (like working on a new feature). Instead of committing this code directly to the main set of files (usually referred to as trunk or master), you can create something called a branch. A branch allows you to create a copy (or snapshot) of the repository that you can modify in parallel without altering the main set. You can continue to commit new changes to the branch as you work, while others commit to the trunk or master without the changes affecting each other.
Once you’re comfortable with the experimental code, you will want to make it part of the trunk or master again. This is where merging comes in. Since the version control system has recorded every change so far, it knows how each file has been altered. By merging the branch with the trunk or master (or even another branch), your version control tool will attempt to seamlessly merge each file and line of code automatically. Once a branch is merged it then updates the trunk or master with the latest files.
For example, let’s say you want to experiment with a new layout for a web site. This may require heavy changes in many files, could break existing code and it may not turn out as expected. It could also take a long time, so you want to continue committing the changes. Instead of committing to the trunk or master set of files, you create a branch. From this point forward, any changes made in the new branch will not affect others in the trunk or master. Days or weeks may go by allowing you to commit changes, test and refine. When the new layout is working properly and you are comfortable with the result you are probably ready to make it a permanent part of the site. This is the point where you will merge the branch with the trunk or master. Once the merge is complete, it will combine the changes from the branch with the most recent version of the trunk or master.
In some cases the version control system might not be able to figure out which change to apply between two revisions when doing a merge. If this happens a conflict will arise. A conflict in this scenario is the same as the conflict mentioned above and requires manual intervention to decide which files or lines of code should remain.
Types of Version Control Systems
The three most popular version control systems are broken down into two main categories, centralized and decentralized (also known as distributed).
Centralized Version Control
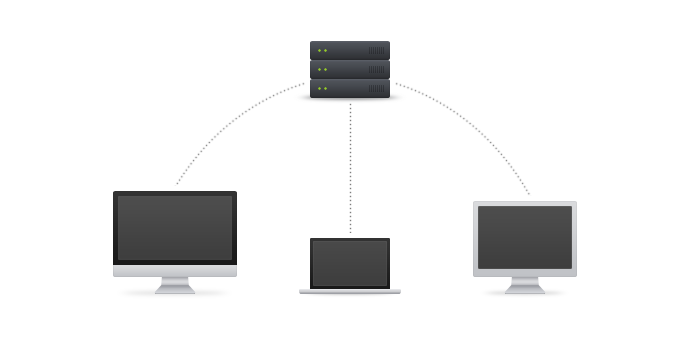
At the time of this writing, the most popular version control system is known as Subversion, which is considered a centralized version control system. The main concept of a centralized system is that it works in a client and server relationship. The repository is located in one place and provides access to many clients. It’s very similar to FTP in where you have an FTP client which connects to an FTP server. All changes, users, commits and information must be sent and received from this central repository.
The primary benefits of Subversion are:
- It is easy to understand.
- You have more control over users and access (since it is served from one place).
- More GUI & IDE clients (Subversion has been around longer).
- Simple to get started.
At the same time, Subversion has some drawbacks:
- Dependent on access to the server.
- Hard to manage a server and backups (well, not with Beanstalk of course!)
- It can be slower because every command connects to the server.
- Branching and merging tools are difficult to use.
Distributed Version Control
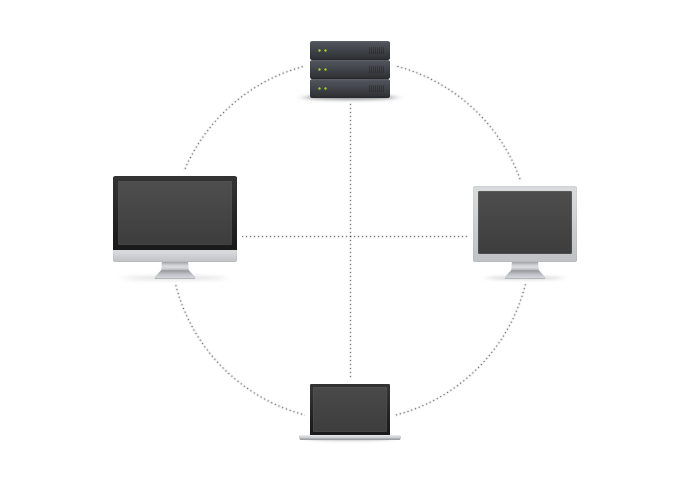
Distributed systems are a newer option. In distributed version control, each user has their own copy of the entire repository, not just the files but the history as well. Think of it as a network of individual repositories. In many cases, even though the model is distributed, services like Beanstalk are used for simplifying the technical challenges of sharing changes. The two most popular distributed version control systems are Git and Mercurial.
The primary benefits of Git and Mercurial are:
- More powerful and detailed change tracking, which means less conflicts.
- No server necessary – all actions except sharing repositories are local (commit offline).
- Branching and merging is more reliable, and therefore used more often.
- It’s fast.
At the same time, Git and Mercurial do have some drawbacks:
- The distributed model is harder to understand.
- It’s new, so not as many GUI clients.
- The revisions are not incremental numbers, which make them harder to reference.
- It can be easier to make mistakes until you are familiar with the model.
Which one is right for you? This really depends on how you work. We usually recommend Subversion if you are just getting started, are not comfortable with the command line or do not plan to do a lot of branching and merging. Otherwise, we encourage you to try Git or Mercurial and see if you like it. With Beanstalk, you’re free to go back and forth as needed without switching hosts.