Introduction
Getting started with Version Control can be an eye-opening experience. You may have already said to yourself, “How did I work without this?”
. Now that you’ve got the basics of Version Control down, you want to start getting really productive by continuing to improve your workflow. Your next step is learning to code in branches.
Coding in branches is a simple practice that keeps you and your work more organized. Branches let you easily maintain your “in-progress” work separately from your completed, tested, and stable code. Not only is this an effective way to collaborate with others, but it will also allow you to automate the deployment of updates and fixes to your servers.
Coding in master/trunk “branches”
Even if you don’t know how to use branching in your development process, you’ve already been using a branch just by committing your code to version control. In all major version control systems, each repo contains at least one branch by default, your working branch:
- in Subversion this is a folder called
trunk, - in Git this is a branch called
master.
Without configuring anything, your first commit to any repository will be made to this working branch.
Each version control system has a different approach to creating, merging, and deleting branches. We’ll be focusing on overall development process, and suggest that you refer to the documentation of your preferred VCS for specific details about commands:
Branching Workflow
Using branches can seem complicated without some guidance. We’re going to help you by focusing on two specific uses for branches and the benefits of having them in your workflow.
Benefits of Branches: Building Features & Fixing Bugs
Most coding falls into one of these two categories: you’re either building new features or fixing bugs in an existing codebase. A problem occurs when those two things need to be happen at the same time.
Imagine that you’ve recently launched big Feature X. Things are going well at first, so you move on to start the next task on your todo list, awesome Feature Y. You start coding and committing changes to your repository, but along the way discover a problem with big Feature X that you need to fix right away. What do you do?
If all of your work is being done in the default working branch of your repository, you’ll need to figure out how to save the work you’ve done so far on Feature Y, revert your repository to the state it was in when you deployed Feature X, make your fix, and then re-introduce your work from Feature Y. This is messy, and you could potentially lose some of your work or introduce new bugs.
Instead, you should be doing all of your work in a feature or bug-fix branches and let the VCS do the hard work for you. You would branch your repository from the point where Feature X was deployed, creating an alternate working copy for you to do new work on. Your Feature Y branch includes the entire repository’s history and code, but a separate history “starts” from the moment the branch is created. This allows you to work on the Feature Y branch, committing to your hearts content, without disturbing the code that you deployed to release Feature X.
Only once the feature is tested and complete, ready for deployment, you can merge that branch back into your main working branch.
This also means you can switch between a feature branch to the default working branch any time to create new branches from that point – like the bug-fix that you need to make. After switching back to the working branch, you would create a bug-fix branch. Working on the bug-fix in its own branch might not seem necessary if the fix is small, but following this practice will help you avoid situations where small bug-fixes turn into bigger bug-fixes, potentially leaving your working branch in a messy state.
Best Practices with Feature & Bug Branches
- Try to avoid committing unfinished work to your repository’s default working branch.
- Create a branch any time you begin non-trivial work including features and complex bug-fixes.
- Don’t forget to delete feature branches once they were merged into stable branch. This will keep your repository clean.
Benefits of Branching: Server Environment Branches
Another reason to use version control is so that you can use your repository as the source to deploy code to your servers. Much like feature and bug-fix branches, environment branches make it easy for you to separate your in-progress code from your stable code. Using environment branches and deploying from them means you will always know exactly what code is running on your servers in each of your environments.
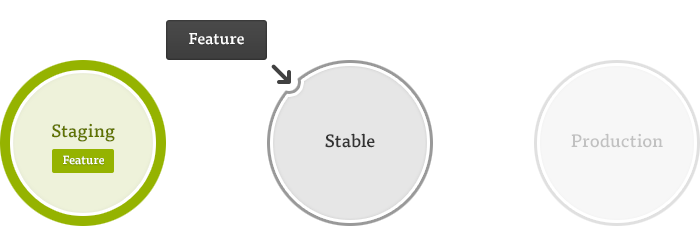
We’ve been talking about your “default working branch” – but you can also think of this as your development environment branch. It’s a good idea to keep this branch clean – this is easily done by using feature and bug-fix branches and only merging them back to your development branch once they are tested. In other words, at any point in time your development branch should contain only stable code. Threfore we will be using the name “stable” from now on in this guide to refer to this branch.
Using Production and Staging Branches
In addition to your development environment, you’re likely to have at least one other environment: production, where your website or application actually runs. Having a production environment branch and making that the only source of code that goes to production ensures that you have a snapshot of what is on your production server at any time, and a granular history of what’s been added to production and when.
In most cases you will have a staging environment as well, where your team or clients can review changes together. Having a staging environment branch will help you keep that environment with the same benefits as a production branch.
Diff Branches for Easy Code Review & Release Notes
When your development environment has been updated with features and bug-fixes that are tested, you can use your VCS to do a diff between your stable branch and staging branch to see what would be deployed that’s not currently on staging. This is a great opportunity to look for low quality or incomplete code, debug code, and other development leftovers that shouldn’t be deployed. This diff can also be helpful in writing your release notes.
Never Merge to Environment Branches Without Deploying
In order to keep your environment branches in sync with the environments, it’s a best practice to only execute a merge into an environment branch at the time you intend to deploy. If you complete a merge without deploying, your environment branch will be out of sync with your actual production environment.
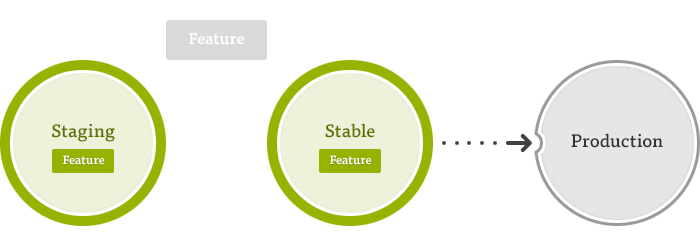
With environment branches, you never want to commit changes directly to the branch. By only merging code from your stable branch into staging or production branches, you ensure that changes are flowing in one direction: from feature and bug-fix branches to stable and staging environments, and from stable to production. This keeps your history clean, and again, lets you be confident about knowing what code is running in which environments.

Best Practices with Environment Branches
- Use your repository’s default working branch as your “stable” branch.
- Create a branch for each environment, including staging and production.
- Never merge into an environment branch unless you are ready to deploy to that environment.
- Perform a diff between branches before merging—this can help prevent merging something that wasn't intended, and can also help with writing release notes.
- Merges should only flow in one direction: first from feature to staging for testing; then from feature to stable once tested; then from stable to production to ship.
Further Reading: Branching with Beanstalk
This is just an overview of some of the most common practices for using branches in version control. If you’re using Beanstalk, we’ve included some resources to help you take advantage of branching.